Data Contract Implementation Patterns
I’ve realized that it’s crucial to explore data contracts in greater depth because, beyond their textbook definition, few truly examine how to implement them in complex and diverse environments — or, more importantly, how to ensure they function effectively and deliver the expected benefits.
In this article, I will discuss various implementation patterns, starting with the most basic and progressively increasing their sophistication.
I won’t spend any time defining a data contract, but I do want to highlight an often-overlooked socio-technical aspect: a data contract serves as a mechanism to hold data producers accountable for how their data is presented and behaves for consumers. Ultimately, it is about establishing true data ownership and formally regulating the discontinuities in ownership along the data transformation chain.
I will outline four implementation options for both batch and streaming data contracts. The first three rely on a platform where metadata about a data contract can be registered, and data quality checks can be performed via connectors. Several data catalogs meet these requirements, so I will refer to “the data catalog” when discussing these three options for simplicity ( so if your data catalog is different, don’t get offended )
The fourth option, however, introduces an alternative pattern that addresses various challenges, which we will highlight and analyze.
Option 1: The Passive Monitoring — batch
This pattern defines Data Contracts within the Data Catalog and enables periodic metadata scans to check for compliance. However, this approach is entirely passive.

Cons:
- Late Detection: Issues are detected only after a periodic scan, meaning consumers may have already used the bad data before the problem is identified. The scan is not synchronized with the data refresh rate.
- System Overload: Increasing the scan frequency to improve breach detection can put excessive strain on infrastructure, leading to higher cloud costs and inefficient resource utilization.
- Change Management Complexity: Managing the data contract requires updates in two separate places — via Git and CI/CD, and within the Data Catalog — at different times, increasing the risk of misalignment.
- Privilege Requirements: The Data Catalog must have the necessary permissions to scan all data contracts across the company.
- No Prevention Mechanism: There is no way to prevent bad data from propagating to downstream consumers before detection.
Personal Comment:
In this case, calling it a “Data Contract” is misleading. This is just traditional metadata and data quality management, offering no real added value.
Option 1 : The Passive Monitoring— streaming
This approach is similar to Option 1 but applied in a streaming context. Streaming is commonly used to regulate data exchange between operational and analytical systems, with mainframe offloading through change data capture being a typical use case. However, this pattern remains entirely passive and cannot stop the data flow in case of issues.

Cons:
- All the drawbacks of Option 1 still apply.
Personal Comment:
Positioning Data Contracts between operational and analytical landscapes is strategic and effective for improving data quality and ownership early in the value chain. However, this pattern only enables monitoring and does not prevent bad data from propagating across different functional areas.
Option 2 : Synchronized Inspection— batch
This is an improvement over Option 1, as it eliminates global scheduling for data contract inspections. Instead, it integrates with the local scheduling of the Data Product — triggering an individual scan immediately after the data refresh is completed.

Pros:
✔ Better synchronization between data refresh and data contract assessment, reducing late detection and computational inefficiencies.
Cons:
- Potential bottleneck: The Data Catalog could struggle to handle hundreds of simultaneous API calls for contract evaluations.
- Change management complexity persists: Updates are still required in two separate places, leading to a risk of misalignment.
- Privilege concerns: The Data Catalog must have permission to scan all Data Contracts across the company.
- Bad data propagation: This pattern does not solve this issue as well.
Personal Comment:
This is a step in the right direction, but it still lacks proactive measures to prevent data issues and avoid the propagation of bad data.
Option 3 : Enforced Compliance — batch
This pattern introduces the Write-Audit-Publish (WAP) mechanism, which blocks the delivery of non-compliant data, preventing consumers from ingesting bad data. This is the key distinction between data quality/observability and the Data Contract pattern: here, the producer is truly held accountable for delivering what was promised.

Pros:
✔ Enables circuit breaking, preventing bad data from spreading — saving time, costs, and operational effort.
Cons:
- Increased complexity at the orchestration level for each Data Product.
- System dependencies: Frequent API calls to the Data Catalog make the system reliant on its responsiveness.
- Mission-critical risk: If the Data Catalog goes down, all the business processes can be impacted — a risk it was never designed to handle.
- Change management complexity persists: Updates are still required in two separate places, leading to a risk of misalignment.
- Privilege concerns: The Data Catalog must have permission to scan all Data Contracts across the company.
Personal Comment:
This is the right approach for implementing a Data Contract in batch mode, but relying on an external platform for all business processes is a poor architectural choice. At scale, it could become a nightmare.
Option 3: Enforced Compliance - streaming
Applying the same WAP principles in streaming is far more complex. In streaming, data is checked continuously (record by record), making it impractical to invoke the Data Catalog for every event. Additionally, the stream processor must also dispatch data based on validation results, meaning it cannot simply act as a passive job triggered by the Data Catalog.

Personal comment
I don’t see a viable way to implement this pattern effectively using an external platform — this is a major limitation.
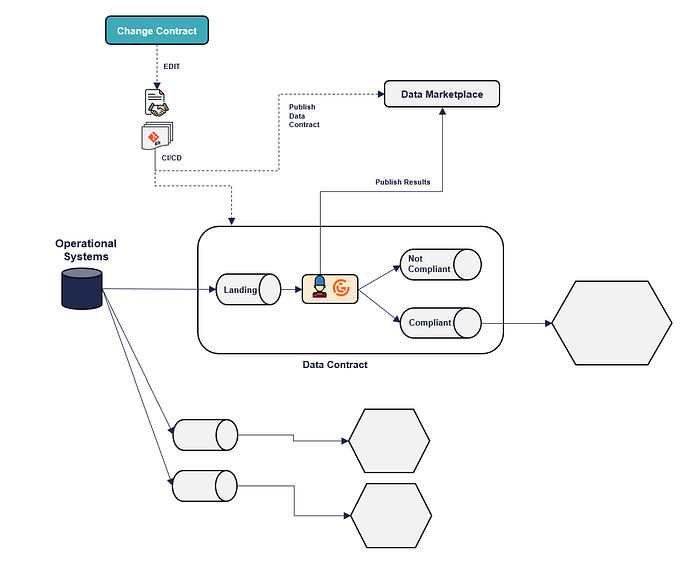
Option 4: Embedded Enforcement — batch
This pattern achieves the same results as Option 3 but with significant improvements:
✅ Enforcement is fully decentralized and self-contained within the Data Product lifecycle; there are no external dependencies and no single point of failure. Each Data Contract is auto-consistent and independent in terms of performance and reliability.
✅ Change management is streamlined into a single source of truth, DevOps friendly, eliminating inconsistencies. The CI/CD, at the same time, creates the proper data contract definition in the Marketplace and creates the physical infrastructure.
✅ The Data Marketplace becomes read-only, removing dependencies and making it a metadata discovery layer.
✅ The monitoring process (the Data Contract Guardian ) runs with a specific service principle that can access only the data of its own data contract, nothing else, improving the overall security.
✅ Simplify scheduling compared to Option 3, removing multiple steps and polling.
✅ No limitations: this pattern can be applied to structured and unstructured data, API and RAG interfaces. There is no dependency on Data Catalog connectors.

Notes:
In this option, I changed “Data Catalog” to “Data Marketplace” to highlight that it is becoming a passive component for discovering and consuming information and is no longer an authoring tool. Said this, this Marketplace can be a Data Catalog tool, too, just disabling edit permissions on data contracts and using DQ reporting capabilities without triggering DQ jobs.
Option 4: Embedded Enforcement — streaming
This pattern achieves the same results as Option 4, but in streaming and allows us to implement what was not possible in Option 3—streaming. At the same time, the Data Contract can inspect and also influence the data flow.
Pros:
- As the Option 4 — batch
Final Thoughts
When a pattern solves a problem sub-optimally, it requires careful consideration. It may meet immediate needs, but what happens at scale?
As someone with a consulting and architecture background, I have always prioritized long-term solutions for my customers. Maybe I’m overcomplicating things, but these real-world scenarios highlight critical challenges that organizations will face.
Example 1: Banking — Liquidity & Risk Management
- A batch-oriented, analytical process integrating hundreds of data sources across multiple business domains.
- The process must be completed within a cut-off time and meet regulatory constraints.
- If data quality or timeliness fails, the bank faces penalties.
- The WAP pattern is essential—errors must be immediately blocked before propagating; otherwise, troubleshooting will be a nightmare. With so many actors and processing steps involved, moving quickly toward identification and resolution is challenging.
- Data Contracts fit perfectly here — but they must be implemented effectively.
Example 2: Energy — Real-Time Infrastructure Maintenance
- IoT devices continuously stream data on physical network conditions.
- Reactive maintenance is time-sensitive — when an alarm triggers, a repair team must be dispatched immediately.
- Bad data can lead to costly errors—sending a crew to investigate a false alarm wastes time, money, and resources.
- In Operational Technology (OT), data errors are common (e.g., due to outages of physical systems).
- If bad data cannot be blocked, incorrect decisions will be made.
- If stopping the algorithm is impossible, monitoring the Data Contract is pointless — the team will still act on bad data.
Implementing Data Contracts effectively is more than just monitoring. True accountability means enforcing proactive measures to prevent bad data propagation. While passive Data Quality and Observability can be useful, they do not achieve the same level of control and reliability as a well-implemented Data Contract enforcement mechanism.

